GitHub - hqweay/orca-plugin-import: 虎鲸笔记导入其它笔记软件的数据库、多维表格
尝试了下虎鲸笔记,难得的一款粒度统一的本地双链笔记软件。比起类 notion 类软件的 database,这也是我目前看到的第一款基于块的 property 做出了多种视图的笔记软件。
何为粒度统一?比方说传统笔记软件会有「文档」「段落」的概念,而在这类软件中「文档」和「段落」被统一为一回事——「块」。统一的好处是什么?比方说用户在打开软件时就不用担心要不要先建立文档——直接开写,因为文档和段落是一回事,用户可以后面方便地将段落转为文档。
既然都是「块」,那么怎么区分「文档」呢?在这类软件中,通过给块赋值一个 property 实现,相当于给块一个标记——你是文档了,那么这个块被当作文档了。
既然能给块赋值「文档」的属性,也就能赋值各种其它的属性。当许多块拥有了属性,就可以通过属性将这些块聚合起来——构成一个 database。
在 notion 类软件的 database 中,database 是一个单独的块,要使用它就需要先建立一个 database,然后将块加入其中。
而在虎鲸笔记这类软件中,通过属性聚合起来的 database 只是一种块呈现方式的视图。
在我看来,后者在开发的工作量上以及设计的统一性上都要更好,后期开发别的视图也更容易……不知道为啥好像真正实现的软件并不多。
同样的,「通过属性聚合」这一操作中的「通过属性」也不是必须的,property 只是给了不同的块一个公共的属性。其它方式也可以达到这一点,比如说「通过标题聚合」「通过缩进层级聚合」。
举个例子,下面只是几种视图,本质上是一个东西。
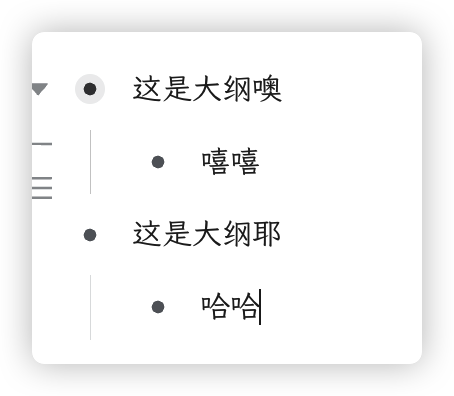
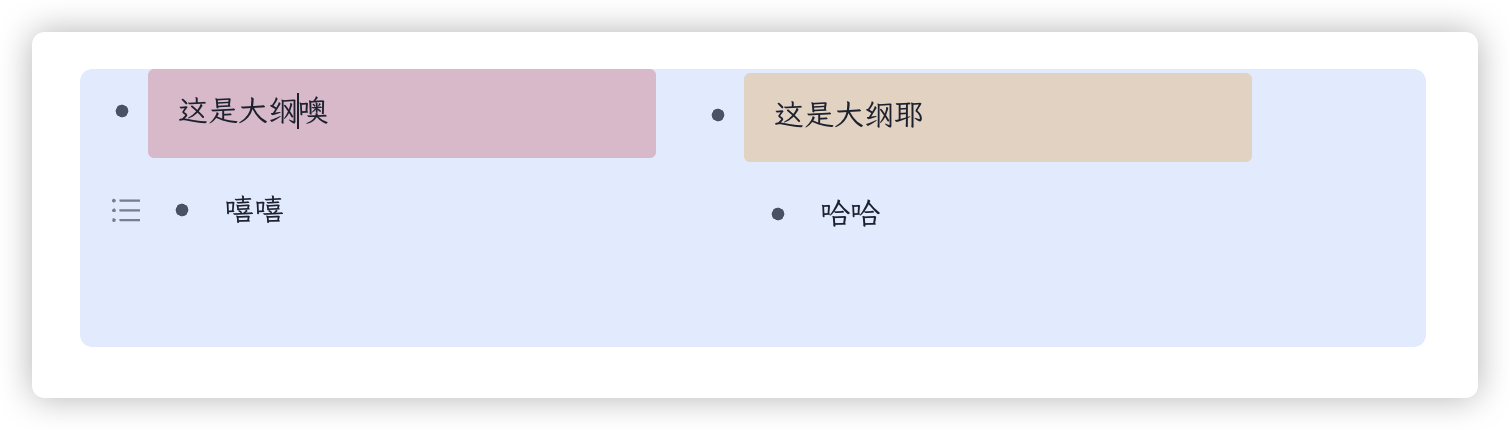
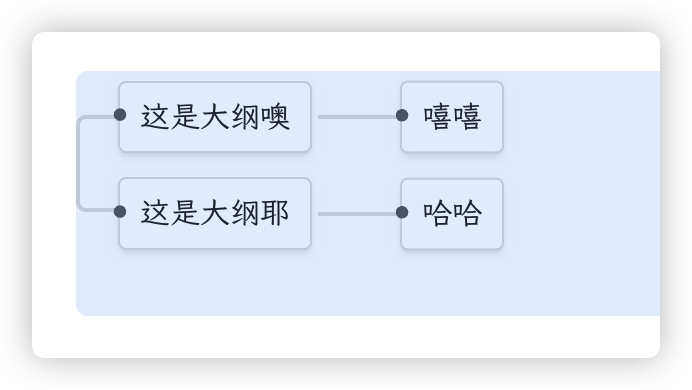

然而此文并非要讨论双链笔记软件的设计,只是基于体验虎鲸笔记,我写了一个将其它笔记软件的 database 导入进来的插件。效果还是不错的,只是数据量在一页达到 700 条(存在图片)后,会有些卡顿。
再 PS:可惜目前虎鲸笔记的查询不支持随机,这真是有点遗憾。随机对于笔记软件,尤其是双链笔记软件来说,对于「回顾环节」起着很大的作用。这类软件的一大优势是记录的无压,然后在这种无压背后如果没有「随机」来为回顾兜底,那么很多记录下来的信息就仅仅是记下来,然后吃灰~